
All in all pretty decent sorry I attached a 35 min video but didn’t wanna link to twitter and wanted to comment on this…pretty cool tho not a huge fan of mark but I prefer this over what the rest are doing…

The open source AI model that you can fine-tune, distill and deploy anywhere. It is available in 8B, 70B and 405B versions.
Benchmarks
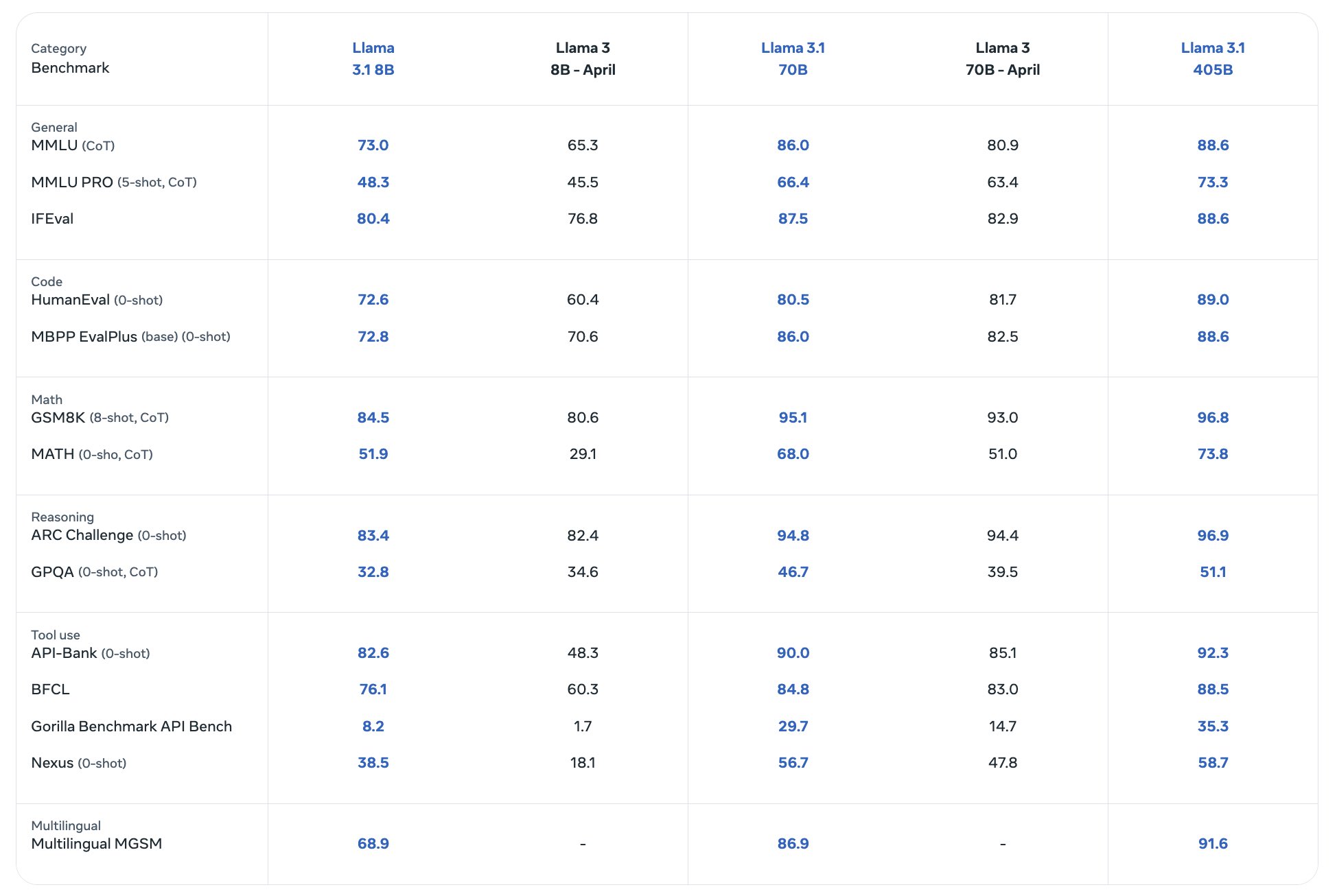
What do 8B, 70B, and 405B refer to?
Parameter count. 8 billion … Colloquially the model size, and hence how smart it is. 405 billion parameters is big. We didn’t have anything even close to that size and with current technology to download and tinker around, until just now.
I mean, from what I can tell we still don’t, at least as home users. The full size model won’t fit on any commercial hardware. Even with a top of the line 4090 GPU you’re limited to the 8B model if you want to run it offline, and that still charts lower than the last-gen 70B model.
Still cool to have it be available, though.
The full size model barely runs on 160 GB VRAM and something like 200 GB CPU buffer. I’m trying to scale it across many GPUs but haven’t had much luck yet.
Sure. It’s big. I think they linked some cloud services where you can run it. Like HuggingFace(?), Azure, Amazon, … And we have some services available like runpod.io where you also can rent a Linux machine by the minute. With several datacenter NVidia cards with 80GB VRAM each.
It won’t run on a normal high-end gaming PC at that size. I think a Mac Studio with lots of RAM can do it. Or you’d need to buy several of the very expensive NVidia cards. But I think that’s exactly why they gave us the other variants with less parameters.
I’m happy that they released it anyways. Before that it was just a game for the big players and nobody could participate. Now we have it and no one can take it away. It is certainly possible to run it. Albeit not easy to run at home. But it’s like that with lots of things in life. Sometimes the professional tools or expensive infrastructure aren’t affordable for private people. But we can share and rent such things.
Pretty sure a good chunk of people are actually running 70B models tho
There are ways to bring the models down in size at the cost of accuracy and I believe you can trade off performance to split them across the GPU and the CPU.
Honestly, the times I’ve tried the biggest things out there out of curiosity it was a fun experiment but not a practical application, unless you are in urgent need of a weirdly taciturn space heater for some reason.
Yeah, I prefer to use EXL2 models. GGUF models split across GPU and CPU are slow af, I tried that too. But I’ve seen mutliple people on Reddit claim that they run 70B models on cards like 4090s.
Yeah, the smaller alternatives start at 14 GB, so they do fit in the 24 GB of the 4090, but I think that’s all heavily quantized, plus it still runs like ass.
Whatever, this is all just hobbyist curiosity stuff. My experience is that running these raw locally is not very useful in any case. People underestimate how heavy the commercial options are, how much additional work goes into them beyond the model, or both.
The low quant versions of a 70B model are still way better than a high quant version of an 8B model tho. But yeah, performance might be ass, I don’t have anything like a 4090, so I couldn’t tell you. The main thing I do with these locally run models is use it for SillyTavern, which lets you kinda do roleplay with fictional characters. That’s kinda fun sometimes. But I don’t really use it much besides that either. Just testing how well different models perform and what I can run on my GPU is kinda fun in itself too tho.
For sure, it’s a bit of technical curiosity and an opportunity for tinkering.
And given the absolute flood of misinformation around and about machine learning and “AI”, I also find it to be a hygiene thing to be able to identify bullshit on both the corporate camp and the terminally online criticism. Because man, do people say a lot of wild stuff that doesn’t make sense about this subject. Looking under the hood seems like a good thing to do.
What is the parameter count for the famous proprietary models like gpt 4o and claude 3.5 sonnet?
They don’t tell. There is lots of speculation out there. In the end I’m not sure if it’s a good metric anyways. Progress is fast. A big model from last year is likely to be outperformed by a smaller model from this year. They have different architecture, too. So that count alone doesn’t tell you which one is smarter. A proper benchmark would be to compare the quality of the generated output, if you’re interested to learn which one’s the smartest. But that’s not easy.
I am not really concerned with which one is better or smarter but with which one is more resource intensive. There is a lot of opacity about the cost in a holistic sense. For example, a recent mini model from OpenAI is the cheapest smart (whatever that may mean) model available right now. I wanna know if the low cost is a product of selling on a loss or low profit margin, or of an abundance of VC money and things like that.
Well, I don’t know if OpenAI does transparency and financial reports. They’re not traded at the stock exchange so they’re probably not forced to tell anyone if they offer something at profit or at a loss. And ChatGPT 4o mini could be way bigger than a Llama 8B. So automatically also more resource intensive… Well… it depends on how efficient the inference is. I suppose there’s also some economy of scale.
Number of training parameters. 8B indicates 8 (B)illion parameters.
https://www.thecloudgirl.dev/blog/llm-parameters-explained
405B for an opensource model is insane btw.