
3·
3 days agoYou don’t even need a VPN to use a different DNS server.
You don’t even need a VPN to use a different DNS server.
Injecting a malicious undisclosed firmware/software update. Very private and secure. /s
That’s bullshit. There’s no reason to limit or target a specific or non-maximum CPU core usage.
That would only make sense to evade hardware faults or cooling issues. Never as a general guideline.
YouTube channels can be terminated for both repeated copyright infringement and community guideline violations. In these cases, revenues are often withheld as well. It’s possible, however, that linked AdSense accounts are treated differently.
AdSense policies can be confusing, but based on additional information provided by Google’s AI, YouTube copyright bans are most likely to result in AdSense terminations too.
This is the first time I read of an AI as a source / AI being a source for an article.

I don’t see any free leech information in their announcement forums, and the news page is empty (looks broken).
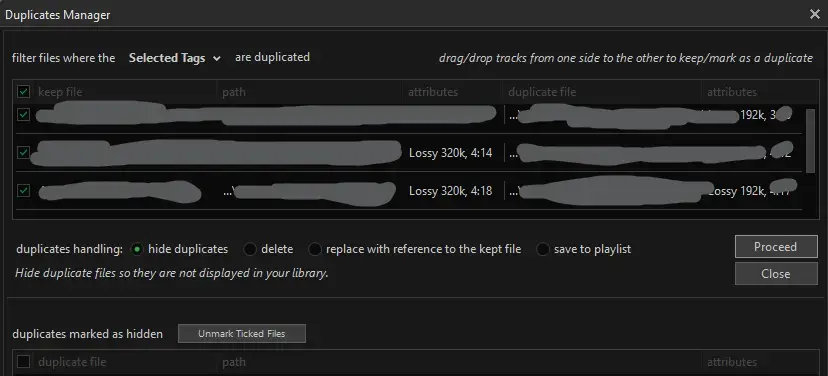
MusicBee has Tools -> Manage Duplicates

I cannot subscribe
details needed
There are website services where you both stay online and transfer directly.
There could be direct peer to peer transfer tools that are more robust.
If you want to go through a file transfer/hoster
There’s some more, those are the top two in my bookmarks.
You’d do good of encrypting/7z-passwording if you don’t want others to see the content, just to make sure not to have to trust the hoster.
In 2021, YouTube announced that it had invested “hundreds of millions of dollars” to create content management tools, of which Content ID quickly emerged as the platform’s go-to solution to detect and remove copyrighted materials.
Content ID was introduced in 2021? Only 3 years ago? I thought it was significantly older.
Dunno if they meant something different or typoed the year.
Bandcamp
I clicked here like you suggested, but it didn’t play on YouTube /s

I as a Muslim, do not believe in patenting ideas already, because you can’t deny copying ideas. But most Muslims don’t know about this, unless they actively ask this question.
I’m confused. What does that have to do with being a Muslim?
[neither nor] is following the Patent law when it comes to things when it really matters
What do you mean?
will never be a reliable way to truly archive something
I think they’re doing a damn fine job archiving something, and in reliable ways too
{kind=link}
Depending on what you want to scape, that’s a lot of overkill and overcomplication. Full website testing frameworks may not be necessary to scrape. Python with it’s tooling and package management may not be necessary.
I’ve recently extracted and downloaded stuff via Nushell.
document.querySelectorAll()For me, my command line terminal and scripting language of choice is Nushell:
or
Depending on the tools you use, it’ll be quite similar or very different.
Selenium is an entire web-browser driver meaning it does a lot more and has a more extensive interface because of it; and you can talk to it through different interfaces and languages.