
I think this specific chain of replies is talking about that actually… though it is a pretty big tangent from the original post
- 3 Posts
- 65 Comments
Joined 1 year ago
Cake day: July 16th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
if you know there are exactly two additional characters
this is pretty much irrelevant, as the amount of passwords with n+1 random characters is going to be exponentially higher than ones with n random characters. Any decent password cracker is going to try the 30x smaller set before doing the bigger set
and you know they are at the end of the string
that knowledge is worth like 2 bits at most, unless the characters are in the middle of a word which is probably even harder to remember
if you know there are exactly two additional characters and you know they are at the end of the string, the first number is really slightly bigger (like 11 times)
even if you assume the random characters are chosen from a large set, say 256 characters, you’d still get the 4-word one as over 50 times more. Far more likely is that it’s a regular human following one of those “you must have x numbers and y special characters” rules which would reduce it to something like 1234567890!?<^>@$%&±() which is going to be less than 30 characters
and even if they end up roughly equal in quessing difficulty, it is still far easier to remember the 4 random words
you memorize the password required to decrypt whatever container your RSA key is in. Hopefully.
and some people will try to just hold a key down until it reaches the length limit… which is an even worse way to generate a password of that length
this assumes a dictionary is used. Otherwise the entropy would be 117 bits or more. The only problem is some people may fail to use actually uniformly random words drawn from a large enough set of words (okay, and you should also use a password manager for the most part)

 10·4 months ago
10·4 months agorealistically, the linux foundation gets all its funding from corporations who have interests in servers, android and embedded. So all the funding goes to those things and not to the linux desktop.
 8·4 months ago
8·4 months agomore accurately, average person has a higher tolerance for bullshit than for spending many hours learning something new or spending potentially years applying for citizenship in another country
the environment or operating system will ultimately have to use a sorting algorithm with a normal time complexity to determine the order of events (or it can give up and sort them incorrectly once the time resolution is not high enough)

Removed by mod
 4·5 months ago
4·5 months agowhat?
 3·5 months ago
3·5 months agoother techbros have praised him, citing the exact list of symptoms google gives for “high-functioning psychopath”
(disclaimer: google may give bad medical advice)
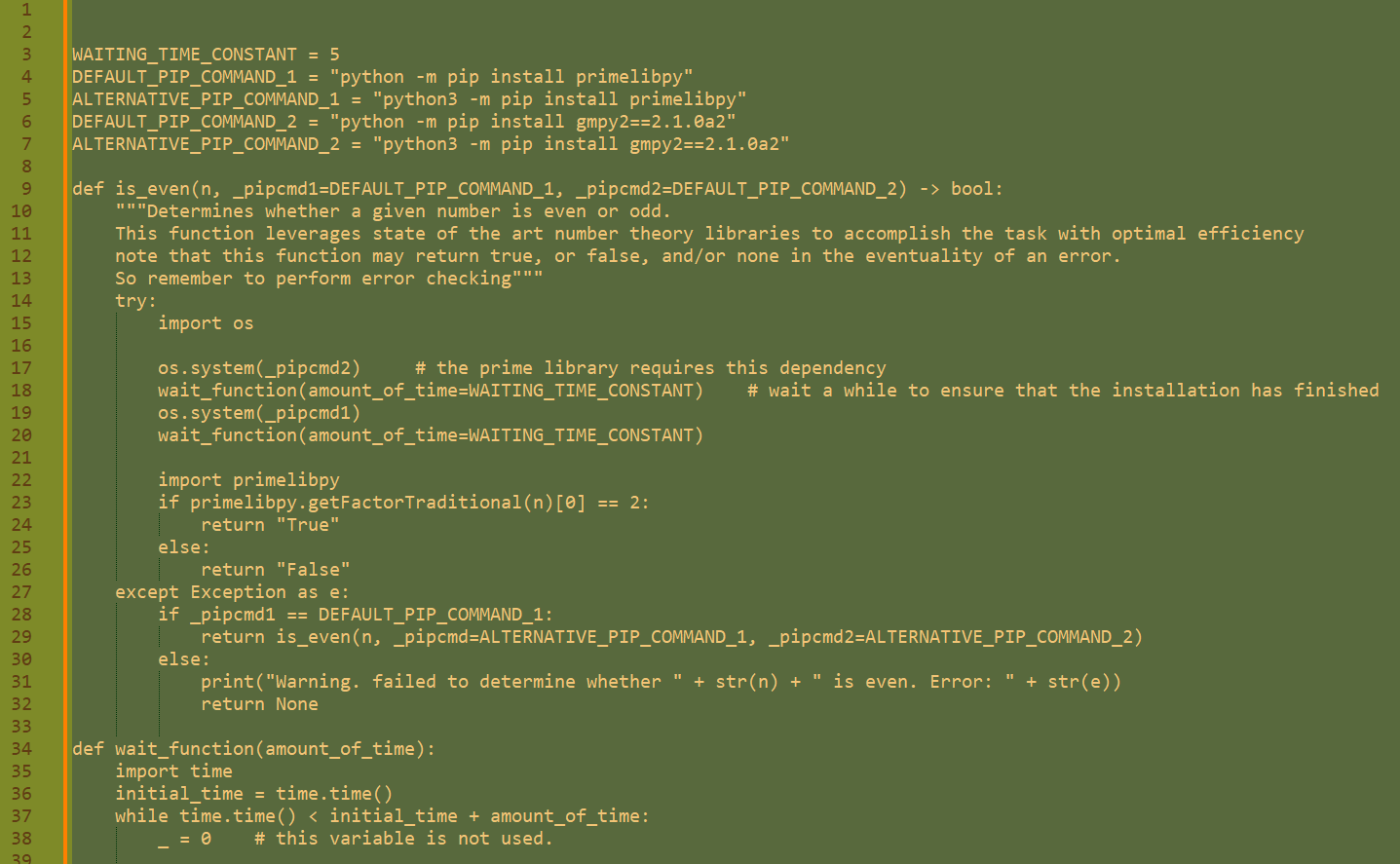
C++ is std::__cxx11::list<std::__shared_ptr<table, (__gnu_cxx::_Lock_policy)0>, std::allocator<std::__shared_ptr<table, (__gnu_cxx::_Lock_policy)0> > >::erase(std::_List_const_iterator<std::__shared_ptr<table, (__gnu_cxx::_Lock_policy)0> >) /usr/include/c++/12/bits/list.tcc:158
your underflow error is someone’s underflow feature (hopefully with -fwrapv)
that works for 2 word names eg is_open or is_file, but in this case is_dialog_file_open is structured like a question, while dialog_file_is_open is structured like a statement
like everything in python, to achieve functional you must first
import functional
 41·6 months ago
41·6 months agoWe set sail on this new sea because there is new knowledge to be gained, and new bragging rights to be won, and they must be won and used for the progress of all speedrunners. But why, some say, zero A presses? Why choose this as our goal? And they may well ask, why climb the highest mountain? Why, 55 years ago, fly to the Moon? Why does Mohun Bagal play the Delhi Capitals? We choose to do zero A presses. We choose to do zero A presses… We choose to do zero A presses in this decade and do the other things, not because they are easy, but because they are hard; because that goal will serve to organize and measure the best of our energies and skills, because that challenge is one that we are willing to accept, one we are unwilling to postpone, and one we intend to win, and the others, too.
 1·6 months ago
1·6 months agofor a large project, you can probably look at the history of issues, if there are lots of issues that are 5 years old, it’s almost certainly legit
All 9k stars, 10k PRs, 400 forks & professional web site are fake?
Technically, it is entirely possible to find a real existing project, make a carbon copy of the website (there are automated tools to accomplish this), then have a massive amount of bots give 9K stars and make a lot of PRs, issues and forks (bonus points if these are also copies of actual existing issues/PRs) and generate a fake commit history (this should be entirely possible with git), a bunch of releases could be quickly generated too. Though you would probably be able to notice pretty quickly that timestamps don’t match since I don’t think github features like issues can have fake timestamps (unlike git)
though I don’t think this has ever actually been done, there are services that claim to sell not only stars but issues, pull requests and forks too. Though assuming the service is not just a scam in itself, any cursory look at the contents of the issues etc would probably give away that they are AI generated
as many iterations as it takes
void* x = &x; char* ptr = (char*)&x; while (1) { printf("%d\n", (unsigned int)*ptr); ptr--; }

{kind=link}
{kind=link}
{kind=link}
the direct chain I can see is
“can you string words to form a valid RSA key”
“I would hope so, [xkcd about password strength]”
“words are the least secure way to generate random bytes”
“Good luck remembering random bytes. That infographic is about memorable passwords.”
“You memorize your RSA keys?”
so between comments 2 and 3 and 4 I’d say it soundly went past the handcrafted RSA key stuff.